Sharing data
First published 25th Feb 2023
Data delivers its value when you move it. Skipping the tedious details, it really delivers value when it excites someone’s sensory organs. Or makes a robot do something. Or both.
How do we move data? In broad brush strokes, you ask, I tell, or I leave it somewhere. Seems simple enough, but there are subtle disadvantages lurking in the shadows.
The example
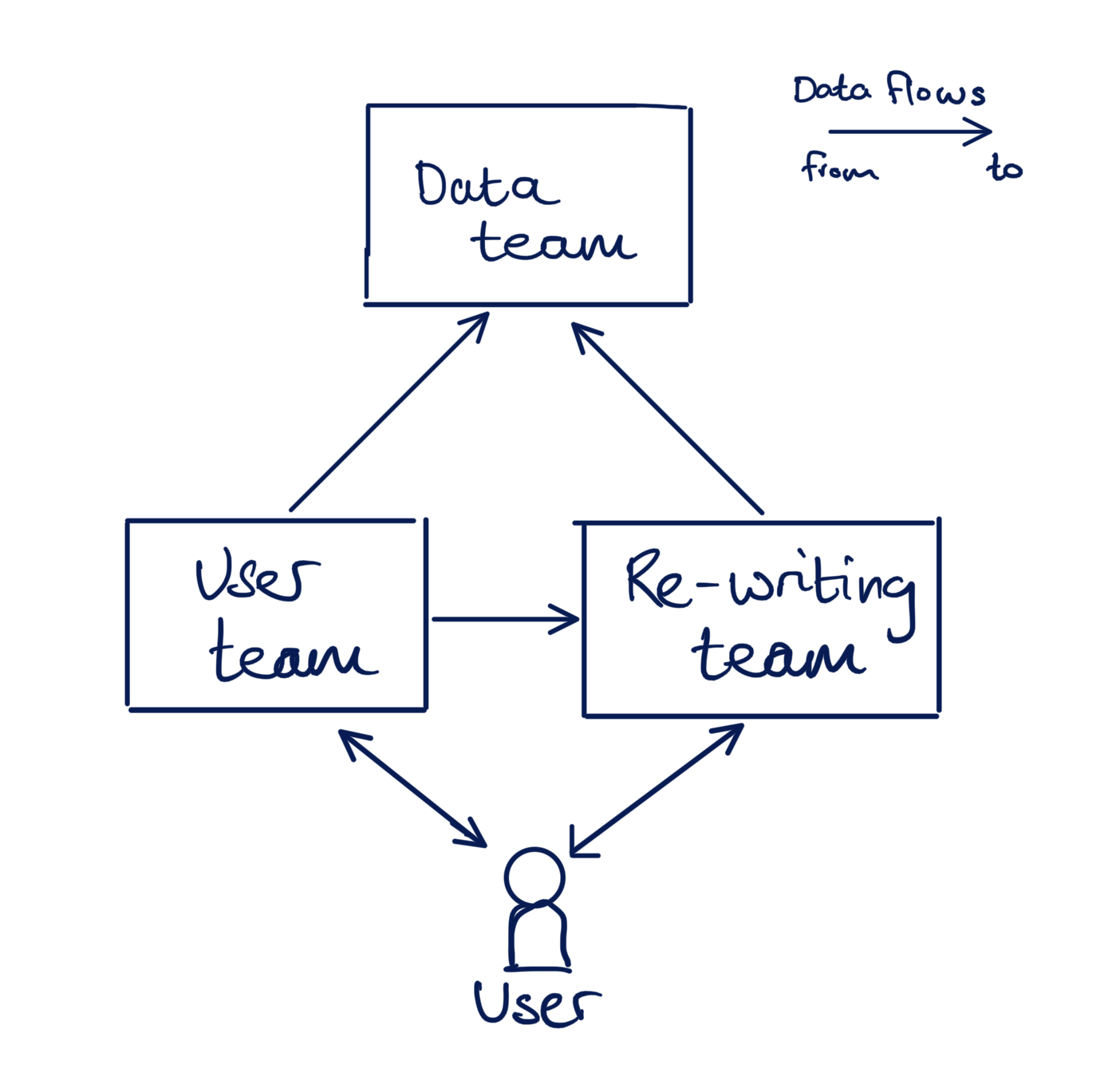
This article is about sharing data between software engineering teams within an organisation. The organisation’s mission is to educate the world by taking the dreary corpus of documents we call science and rewriting it so that it’s a pleasure to read[1]. Users can sign up to the service and request an article be re-written. Don't sweat the details of who stores what, they're only there to add flavour to the example. There are three engineering teams:
- The User team
- The Data team
- The Re-writing team
The User team is responsible for handling information about a user:
- Id
- Name
- Email address
- Subscription information
The Re-writing team takes requests for translations and distributes the work to a team of re-writers. They store the following:
Translation Requests:
- User id
- Document doi
- Status (pending, translated, rejected)
Document Library:
- Document doi
- Translation (LATEX file + images, etc)
The Data team centralises the company’s data for analysis. They store:
- a copy of everything
The teams want to move independently of each other, so they’ve made the tradeoff to split their technology into separate services — i.e. not a monolith[2]. If they want data, they have to get it from the team that owns it.
The organisation is staffed by people who have been around the block a few times; they understand that:
- a given entity, such as a user, should have a single source of truth
- you only write changes to the source of truth[3]
- copying data and keeping it in a local cache is allowed, but it comes at a price (more on this later)
Sharing is caring
As we said earlier, there are three ways to share data: you ask, I tell, I leave it somewhere. Details vary, and in your context those details might matter, but the general shape of the solutions will be the same.
Examples of different data sharing methods:
| Ask | Tell | Leave | |
|---|---|---|---|
| Sync | HTTP GET | HTTP POST | n/a |
| Async | Polling | n/a | Pub/Sub |
Most of the examples are self explanatory, but one of the categories is worth further subdividing. Asynchronous ways of leaving data somewhere:
| Ephemeral[4] | Semi-Persistent[5] | Persistent[6] | |
|---|---|---|---|
| Async | RabbitMQ, Google Pub/Sub, AWS SNS | Amazon Kineses | Apache Kafka, Data Warehouse table, Tuple spaces[7] |
These methods are common enough that I'll spare you the explanation of how they work and their advantages. The less commonly understood method is using a persistent log, check out this video of Martin Kleppmann explaining “turning the database inside out” for a brilliant explanation of the challenges involved in moving data around.
Tradeoff time
The tradeoffs come creeping out of the woodwork when you start sharing data — usually after you’ve built everything and it’s too late to turn back. We’ll explore:
- Undesirable coupling
- Eventual consistency
- Reading your own writes
- The problem of when
- Schema evolution
Coupling
Data is like communicable disease, the more coupled your systems are, the more ways there are to be infected.
Who, why, what, where, when and how. Coupling can occur by knowing about other systems (who), caring what they’re trying to achieve (why), the format of the data (what), where the other systems live — i.e. URL’s (where), the time the request takes place (when), and the specific technology/protocol/version (how).
The more of these couplings you have to consider for your given method of data sharing, the more complex your system is. The more complex it is, the more failure modes it has and the harder it is to understand.
Let’s explore this coupling in an example. The Data team need to know about all the users. Let’s imagine the Data team asked the User team to send them an HTTP POST whenever a new user is created. They are coupled by:
- Who: the User team knows about the Data team
- What: the format of the data, because the POST body must be the format that the Data team will accept
- Where: we have to POST to a specific URL, just for this purpose
...data-team.org-name.com/... - When: the Data team will have to accept the information when the User team provide it
- How: they will have to agree on protocol (e.g. HTTP POST).
That’s a lot of coupling. Why does it matter? Imagine a new user signs up, here’s the happy path:
- Start transaction
- Write user record to user table
- POST the Data team the user info
- Commit the transaction
What if step 3 fails[8]? The choices are:
- Reject the user request; roll back the transaction. Sorry, no sign ups today, the Data team have an outage.
- Write the new user to the database and:
- forget about the Data team, or
- retry this request later
All those choices suck, and the last one is the only one I’d entertain in most circumstances.
Imagine you had a similar arrangement with the Re-writing team. You have all the downsides x2.
The final twist of the knife is that the User team needs to spend precious cognitive energy caring about the Data team. Caring isn’t cool. Sadly, they have to care because they need to know if it’s ok to skip the POST to the Data team on failure. The why we didn’t list above is now added to the list. Eugh. They split the teams up so they could move independently, not distract each other with their concerns in endless meetings.
There is another pernicious form of coupling, this one occurs when using HTTP GET to share data. The provider of the data now has the uptime and robustness requirements of their neediest user. If one single consumer needs to be five nines resilient, then you do too. If you have GET requests flying around between many teams then failure is likely.
If one consumer uses your GET API as part of a batch job, and that consumer is too trigger happy with the concurrency, you’re database is going to blow a gasket. How much control do you have over this? Not much.
Using HTTP to share data is a common pattern. This means there are many solutions to these problems, but take a step back and make sure you’re implementing solutions to a problem you need to have. Consider decoupling your teams in time and place; use a queue to share data instead.
Consistency
Imagine you’re a user of this fantastic re-writing service and the engineering team at this company took the coupling concerns seriously; they decided to use a pub/sub system to share data instead of HTTP GET APIs. You go to the user profile page to update your email address, you then request a document translation and the confirmation goes to your old email address. What the…?
If the Re-writing team store a local copy of the user information, then it is guaranteed, by nothing less than the laws of physics[9], that there will be a delay between when an update is written and when the copy is refreshed. This is known as eventual consistency. It’s why nothing ever works properly. The desirable property, which this type of caching sorely lacks, is known as being able to read your own writes.
When
Time is like one of those friends who never misses an opportunity to get one over on you. Here are the ways it conspires to get you.
The way of the new team.
You’ve recently put the finishing touches on your pub/sub system. The dead letter queues are in place, you’ve eliminated the race conditions, the system is working well and the Customer Service team are recording an all time low in the number of complaints about missing data.
Things are going a little too smoothly and management are nervous about what the engineers will do if they have too much time on their hands. They decide to create a new team. The team will re-write overly long and boring technical blog posts by second rate engineers who fancy themselves as writers, with a focus on websites with questionable background colours.
This team comes along and — you wouldn’t believe the gall — they’ve hooked themselves up to your pub/sub topic, but they want users who signed up before the team existed. Before you know it, you’re in another meeting explaining the complexities of catching up with a live pub/sub feed. You also have to find a way to dump the existing database so the new team can read it.
The way of the buggy integration.
The Re-writing team are getting reports of strange behaviour. The re-writing browser page is crashing when certain users try to load it. They investigate and realise there are users who exist in the User database but not in their local copy. The pub/sub queues aren’t backing up so there must have been a bug at some point.
They find the bug, fix it, and realise they need to reconcile their copy against the user database. Another meeting later, the User team explain the same thing to the Re-writing team as they did to the new team and a back-fill takes place. This causes tremendous problems because the service has become rather popular and syncing all the users takes a long time.
In summary: if you use a pub/sub system, you should must not assume that you’ll only need to share the data on creation and update. If you use a persistent log[10], you’re no longer beholden to this issue because it can be read from beginning to end by anyone at any time.
Time is a sophisticated adversary; when has another way to sneak up and bite. If you send a pub/sub message or write to a data warehouse table, you have no idea when someone will read that data. It could be milliseconds later, but it’s possible the read happens days or years after the write. If your payload/row/message has an attribute like { … “hasAccessToProduct”: true }, it could be dangerous, meaningless, or both.
You could add context about when that attribute applies or avoid structuring the data that way. If you rely on someone reading the message soon after it’s been written, you’ve allowed yourself to become re-coupled in time. Be careful.
The final way that time sticks its oar in and stirs the pot is around message ordering. Most pub/sub systems don’t have strong ordering guarantees. Even if they do, if you have multiple nodes of your service writing to a topic, it’s hard for you to guarantee what order you’re writing messages. Use something that’s capable of providing a monotonic number (a PostgresSQL sequence will suffice) and put the sequence number on your messages. Consumers will need to be aware of out of order messages and how to handle them
Schema evolution
The problem of schema evolution applies to all methods of sharing data. Here are some tips:
- Version your schema, put that version in the message/topic/payload/route.
- Wrap things in an object, even if you don’t think you need to. Adding keys to an associative data structure is a backwards compatible change.
{ "data": [...] }not[...]. - Pick the attributes you care about from shared data, don’t assume new keys won’t be added. Never (read “extremely rarely”) reject a request/response because it has extra keys you don’t know/care about
- Tell the truth. Call things what they are, not what you wish they were or what they’re going to be used for. This way you’re less likely to need to evolve your schema. For example, if you capture an event every time the user gives feedback, call it
{ "starsGiven": 1}not{"askCustomerServicesToContactUser": true}.
Summary of tradeoffs
| Coupling | Consistency | Schema evolution | Out of order messages | New consumers | |
|---|---|---|---|---|---|
| HTTP GET | high | good | ok | no | ok |
| HTTP POST | high | good | ok | no | ok |
| Pub/Sub | low | eventual | harder | yes | hard |
| Persistent log | lowest | eventual | hardest | yes | trivial |
Conclusions
Sharing data is a matter of balancing tradeoffs. There’s no single right answer, nor a sensible default way of doing it. It depends on context. How many teams do you have? What service are you offering? How resilient is your product to eventual consistency? What are the consequences of failure? How quickly do you need to move? What kinds of change are likely?
The companies and teams that make up the bulk of my professional experience benefit from lower coupling. If those teams can focus on the work that justified making them a team in the first place, they can move faster and add value more effectively. This can be achieved for the price of learning how to mitigate the downsides of sharing data using methods like pub/sub or persistent logs. This allows the teams to do their work with no concern for what the other teams are doing because they’ve shared their data with anyone who needs it in a lowly coupled way.
It’s hard to know at what level to pitch an article, and this one is pitched pretty high. If you didn’t understand everything or don’t have experience with all the systems I’ve referred to then that’s on me, don’t be disheartened. I recommend Designing Data Intensive Applications - Martin Kleppmann if you want to learn about this topic in more detail.
Too many science papers use a complex, narcissistic style of writing that borders on illiteracy. It’s so normal to write in this style that respectable journals publish auto-generated articles by mistake! ↩︎
A single deployable artefact (like a NodeJS web service) and database that everyone in the company shares ↩︎
…lest you spend eternity burning in the firey pits of Hell. ↩︎
Once you’ve read the message once, it’s gone. ↩︎
You can read the message more than once, but it’s only stored for a limited amount of time. ↩︎
You can read the message forever. ↩︎
I barely know anything about these, but I think they fit into this category and sound very cool. ↩︎
This is impossible to ascertain with certainty, the response to the successful POST may have been lost ↩︎
Ignoring all that stuff about spooky action at a distance and assuming you haven't slipped into a state of psychosis and decided to implement a distributed transaction. ↩︎
Like Apache Kafka ↩︎